Case B: Describing trends in DD and event study designs
Introduction about design-based studies
Another case where data visualizations can be of particular utility is in the context of describing average levels or change over time in a design-based study of some type.
Motivation: how to effectively convey change, parallel trends and treatment heterogeneity
There are a few big reasons why it is useful to use visualizations within this type of research design and analysis.
First, these methods depend on change over time for estimating average treatment effects on the treated. Describing change over time is one of the most common uses of data visualization, with a line plot being perhaps the most commonly employed option. So to start, this is a context where we don’t have to be as worried about figures being unexpected or likely to perplex readers.
Second, if relevant, the parallel trends assumption is something that we’d like to assuage reviewers’ and readers’ concerns about and it turns out that we can fold empirical tests related to this assumption into our visualizations quite easily. We don’t always have the capability to test for anticipatory effects pre-treatment, but when we do this is no doubt an important element to why visualizations are effective for difference-in-difference or event study designs.
Third, if relevant, we want to be able to illustrate treatment heterogeneity based on groups having different starting points to their treatment as well differences in length of exposure. Such heterogeneity can become difficult to assess in tabular forms, which may be less true of relatively simple DD designs, but with the use of visualizations, things like group-time specific average treatment effects can be more intuitive.
How do we get there?
We will be focusing on making plots that visualize either trends over time for the treated and control groups of a design based study, or just the difference in trends between these two focal groups.
For relatively simple designs, it’s straightforward to estimate the models and make predictions using the fixest library, which handles incorporating fixed effects and clustering errors quite conveniently. However, once we move towards more complex designs where we model treatment heterogeneity and dynamic treatment effects, in such cases there is a very useful package called did that provides a convenient means for estimating these models.
Setup
Software dependencies
library(tidyverse) #dplyr, ggplot2## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──## ✓ ggplot2 3.3.5 ✓ purrr 0.3.4
## ✓ tibble 3.1.6 ✓ dplyr 1.0.8
## ✓ tidyr 1.2.0 ✓ stringr 1.4.0
## ✓ readr 2.1.2 ✓ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(fixest) #for simpler DD models
library(did) #for event study models
library(broom) #quickly process model outputData
Fake two-period DD data
#first let's simulate some simple two period DD data to model
set.seed(20220418)
#make the 2 period data
sim_2_period_param <- reset.sim(time.periods = 2)
sim_2_period <- build_sim_dataset(sim_2_period_param)
#look at the simulated data
glimpse(sim_2_period)## Rows: 6,816
## Columns: 7
## $ G <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,…
## $ X <dbl> 0.3252394, 0.3252394, -0.2484243, -0.2484243, 0.2038793, 0.203…
## $ id <int> 1, 1, 2, 2, 4, 4, 7, 7, 8, 8, 10, 10, 13, 13, 15, 15, 17, 17, …
## $ cluster <int> 15, 15, 23, 23, 6, 6, 49, 49, 3, 3, 20, 20, 25, 25, 13, 13, 49…
## $ period <dbl> 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1,…
## $ Y <dbl> 3.0012710, 5.3261926, 2.4214177, 2.9075177, 3.0204852, 5.21777…
## $ treat <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…Real-world event study data
The other data that we will look at are from a recent study about using difference-in-difference designs where there are multiple tiem periods of observation and treatment heterogeneity among the group receiving the intervention. These data are a strongly-balanced panel covering 500 U.S. counties observed across 5 time periods (2003-2007). The study these data are drawn from analyzes the effect of minimum wage policies on teen employment, and since the laws were passed at different times there is a need for an event study design that considers these differences in exposure timing and length.
Callaway, B., & Sant’Anna, P. H. (2021). Difference-in-differences with multiple time periods. Journal of Econometrics, 225(2), 200-230.
mpdta <- read_csv("./data/mpdata.csv")## Rows: 2500 Columns: 6
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (6): year, countyreal, lpop, lemp, first.treat, treat
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(mpdta)## Rows: 2,500
## Columns: 6
## $ year <dbl> 2003, 2004, 2005, 2006, 2007, 2003, 2004, 2005, 2006, 2007…
## $ countyreal <dbl> 8001, 8001, 8001, 8001, 8001, 8019, 8019, 8019, 8019, 8019…
## $ lpop <dbl> 5.896761, 5.896761, 5.896761, 5.896761, 5.896761, 2.232377…
## $ lemp <dbl> 8.461469, 8.336870, 8.340217, 8.378161, 8.487352, 4.997212…
## $ first.treat <dbl> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…
## $ treat <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…Dependent variable
The outcome is the log of teen employment from 2004 to 2007, taken from the Quarterly Workforce Indicators (QWI).
summary(mpdta$lemp)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.099 4.868 5.697 5.773 6.684 10.443What are the trends over time?
Two period
Starting with the simulated 2 period data, this sort of plot is probably the most common for two period data.
#summarize the mean values before and after treatment
dd_2_period <- sim_2_period %>%
group_by(period, treat) %>%
summarize(mean_Y = mean(Y))## `summarise()` has grouped output by 'period'. You can override using the
## `.groups` argument.ggplot(dd_2_period, aes(x = period, y = mean_Y, shape = factor(treat), group = treat)) +
geom_line() +
geom_point(size = 2)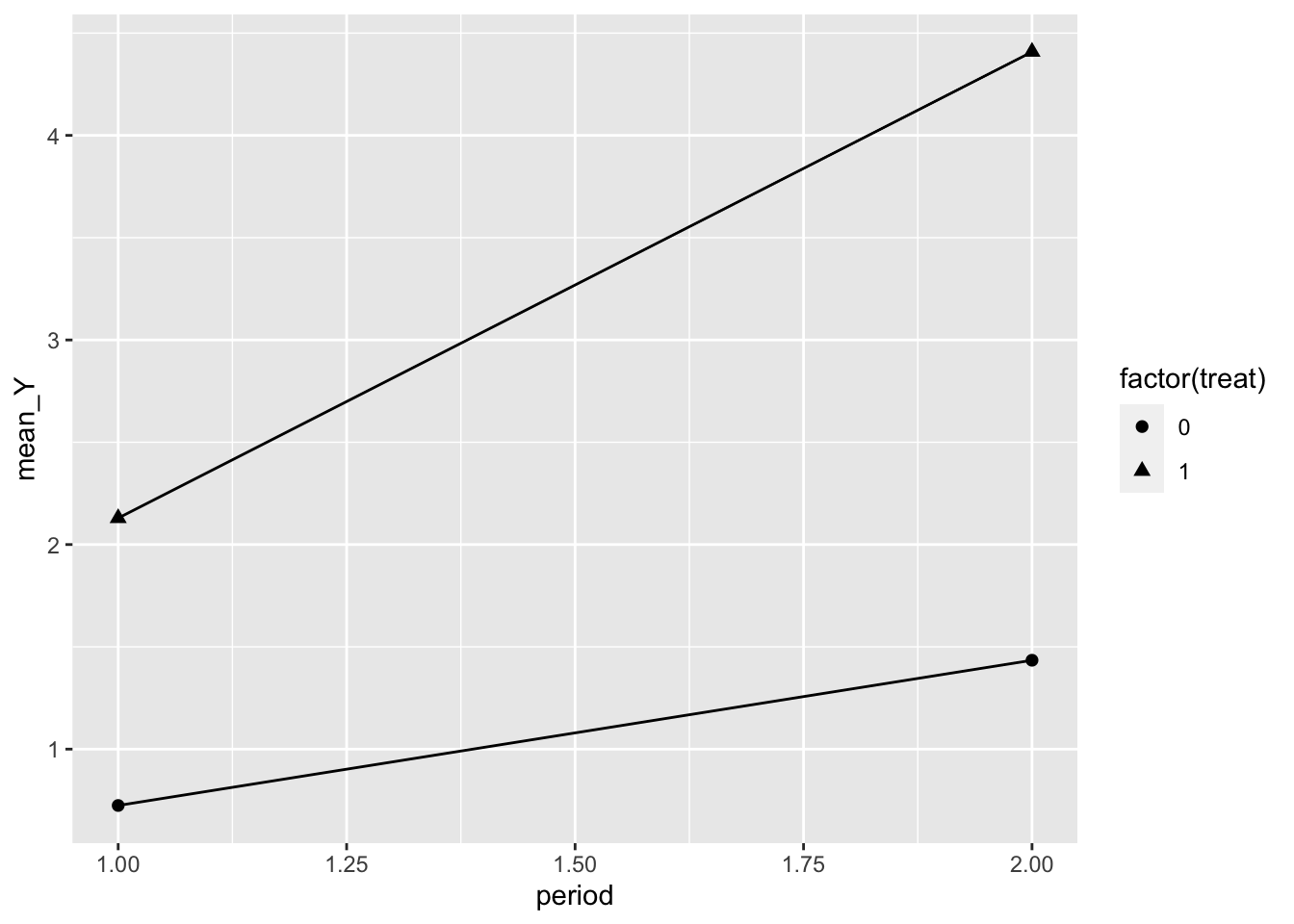
In some instances you see a counterfactual line added to denote what we expect the post treatment value to be under the assumptions of the DD model, and this can be added relatively easily.
dd_2_period <- dd_2_period %>%
group_by(treat) %>%
mutate(chg = mean_Y[period == 2] - mean_Y[period == 1]) %>%
ungroup() %>%
mutate(cf = ifelse(period == 1, mean_Y, mean_Y[period == 1] + chg[treat == 0]))
ggplot(dd_2_period, aes(x = period, y = mean_Y, shape = factor(treat),
group = treat, linetype = "Observed")) +
geom_line() +
geom_line(aes(x = period, y = cf, linetype = "Counterfactual")) +
geom_point(aes(x = period, y = cf), size = 2.5) +
geom_point(size = 3) +
scale_x_continuous(breaks = c(1, 2), labels = c("Pre-treatment", "Post-treatment")) +
scale_shape_discrete(labels = c("Control", "Treated")) +
scale_linetype_manual(values = c(2, 1)) +
labs(x = "", y = "Average Y\n", shape = "", linetype = "") +
theme_bw() +
theme(panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank())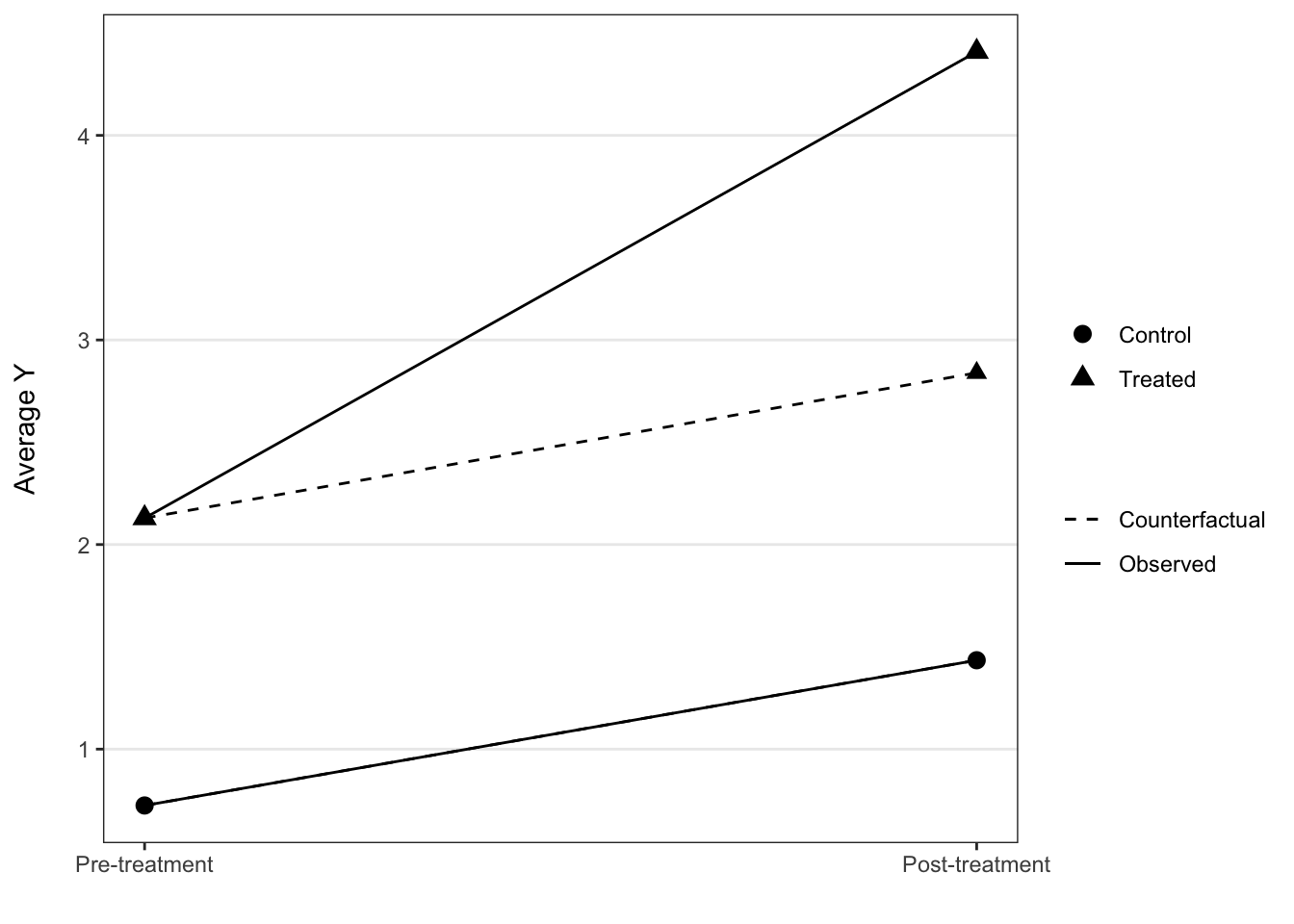
Multiple periods
This sort of visualization extends to the use case of having multiple time periods, with the important assumption that the treatment timing is still uniform across groups.
To demonstrate this, here we visualize the multiple-period mpdta using only the control cases and cases where treatment began in 2006. This is obviously just for demonstration and we wouldn’t throw out the other cases in practice, but it’s fairly clear what is going on in this plot.
Still, since the trends are relatively muted compared to difference in level over time, this is a case where we might start to prefer a plot looking just at the difference in trends between the two groups at each of the periods. This would help to scale the y-axis such that the changes are more perceptible, though as it stands right now the change in trends starting with treatment is still pretty easy to see.
means <- mpdta %>%
filter(first.treat %in% c(2006, 0)) %>%
group_by(year, treat) %>%
summarize(lemp = mean(lemp))## `summarise()` has grouped output by 'year'. You can override using the
## `.groups` argument.ggplot(means, aes(x = year, y = lemp, group = treat, shape = factor(treat))) +
geom_vline(xintercept = 2006) +
geom_line() +
geom_point(size = 2.5) +
scale_shape_discrete(labels = c("Control", "Treated")) +
theme_bw() +
theme(legend.position = "bottom",
panel.grid.minor = element_blank()) +
labs(x = "", y = "Logged Teen Employment\n", shape = "")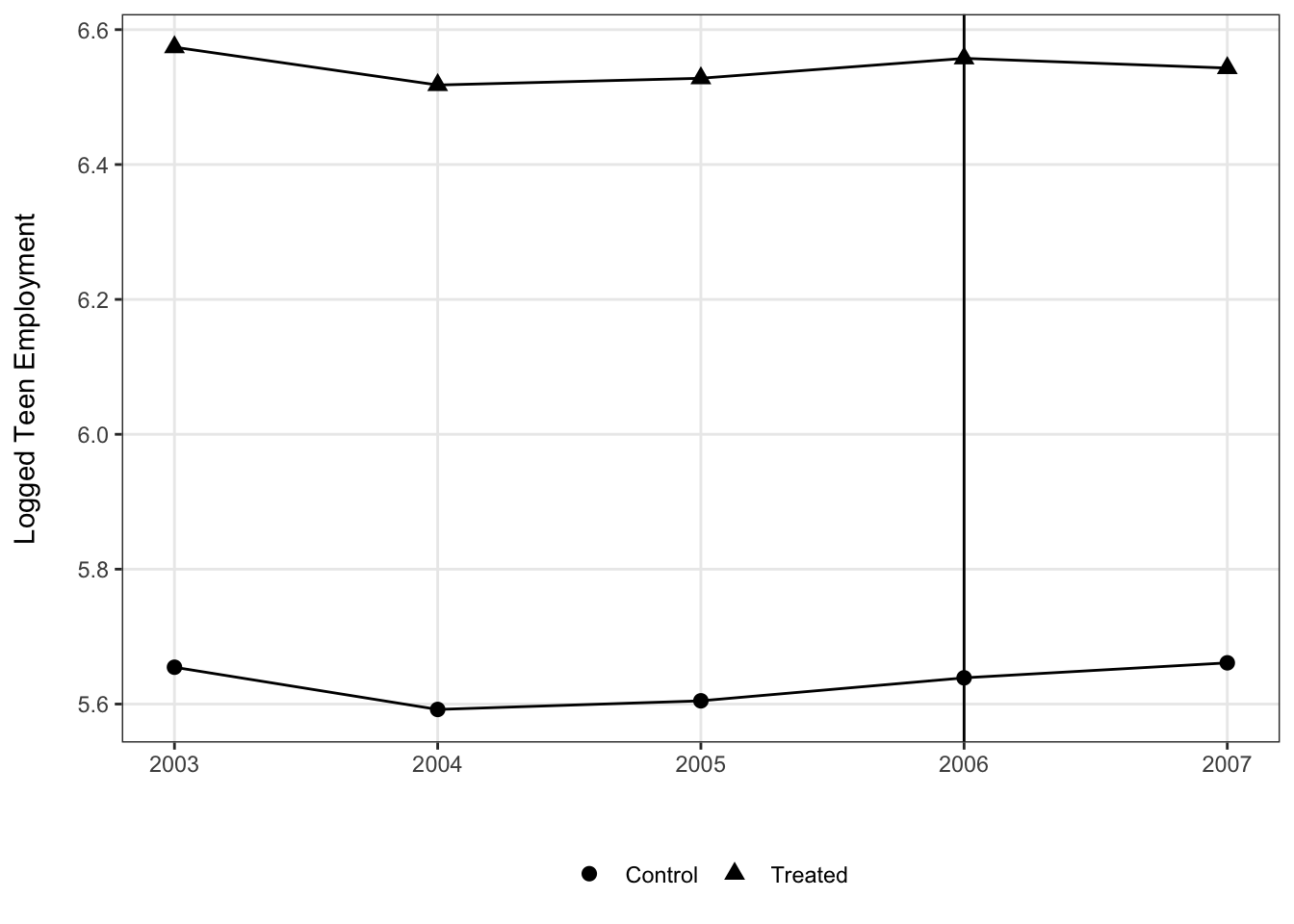
In contrast, with treatment timing we have to retool things a bit. The result is not quite as simple since the small multiples are needed, but by overlaying the control group in each panel it is easier to make the implied comparison than if we had a separate panel for those cases.
means <- mpdta %>%
group_by(year, first.treat, treat) %>%
summarize(lemp = mean(lemp)) %>%
ungroup() %>%
mutate(first.treat = ifelse(first.treat == 0, NA, first.treat)) %>%
rowwise() %>%
mutate(first.treat.chr = case_when(
is.na(first.treat) ~ list(c(2004, 2006, 2007)),
TRUE ~ list(unique(first.treat)))) %>%
ungroup() %>%
unnest(first.treat.chr)## `summarise()` has grouped output by 'year', 'first.treat'. You can override
## using the `.groups` argument.ggplot(means, aes(x = year, y = lemp,
shape = factor(first.treat), linetype = is.na(first.treat),
group = factor(first.treat))) +
facet_wrap(~ paste("First Treated:", first.treat.chr)) +
geom_vline(aes(xintercept = first.treat)) +
geom_line() +
geom_point() +
geom_point() +
scale_linetype_discrete(labels = c("Treated", "Control")) +
scale_shape_discrete(na.value = 4, labels = c("2004", "2006", "2007", "Control")) +
theme_bw() +
theme(legend.position = "bottom",
panel.spacing = unit(.2, "in"),
panel.grid.minor = element_blank()) +
labs(x = "", y = "Logged Teen Employment\n", linetype = "Treatment Group") +
guides(shape = "none")## Warning: Removed 15 rows containing missing values (geom_vline).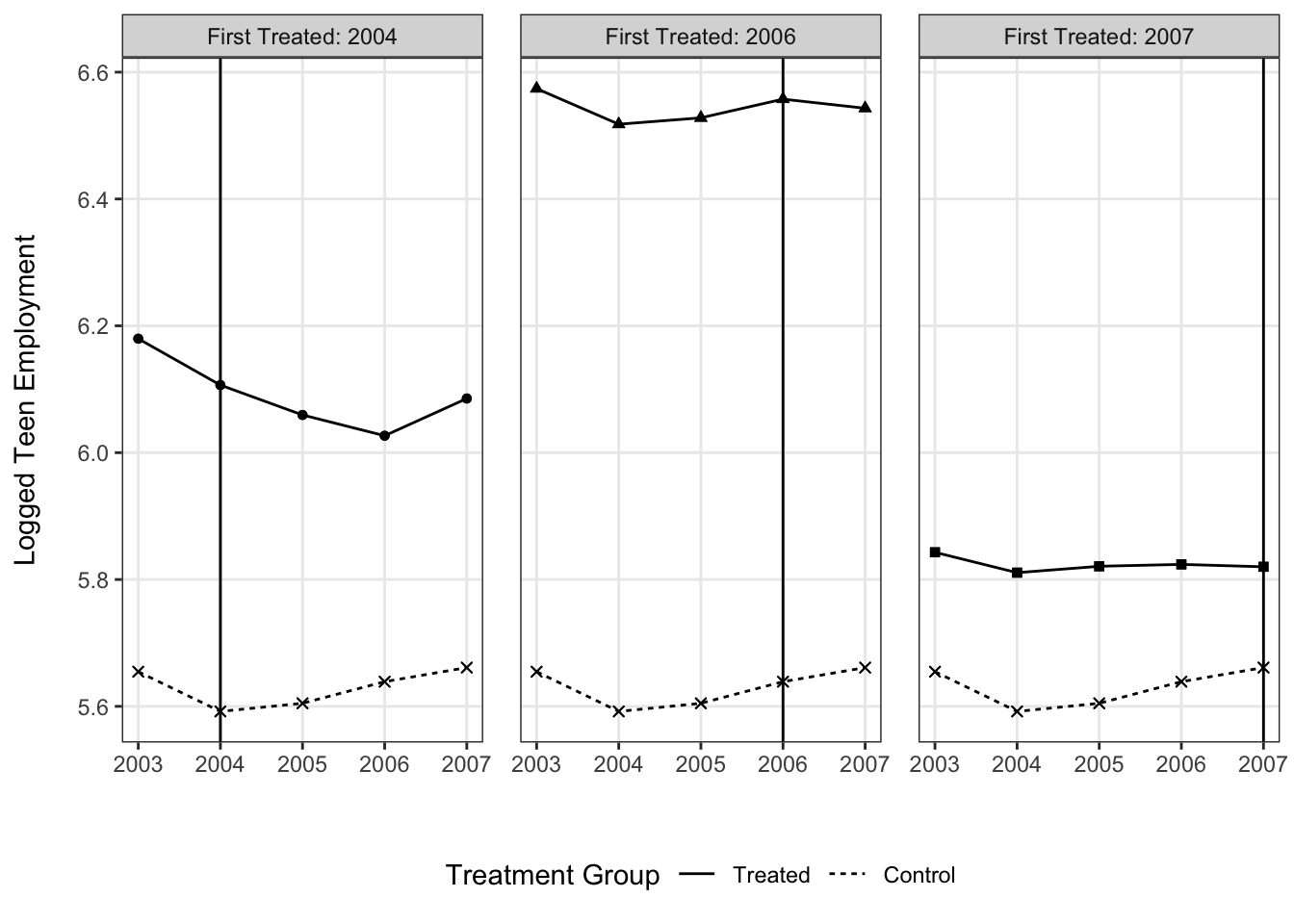
What are the average treatment effects?
Two time periods
Since a two period design produces a single estimate for the ATT, this is really a case where graphics don’t offer much beyond conveying this information through a table if our focus is on a single model.
#estimate TWFE
model_2period <- feols(Y ~ period * treat | id, sim_2_period)## The variable 'treat' has been removed because of collinearity (see $collin.var).#give the summary info
summary(model_2period)## OLS estimation, Dep. Var.: Y
## Observations: 6,816
## Fixed-effects: id: 3,408
## Standard-errors: Clustered (id)
## Estimate Std. Error t value Pr(>|t|)
## period 0.709973 0.040592 17.4905 < 2.2e-16 ***
## period:treat 1.569548 0.057843 27.1348 < 2.2e-16 ***
## ... 1 variable was removed because of collinearity (treat)
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## RMSE: 0.84385 Adj. R2: 0.786127
## Within R2: 0.496142Now it is common to have multiple models due to including covariates, looking at particular subgroups or other reasons, and in these cases there could be value to presenting the focal information about the ATT provided by the different models’ DD coefficients in a visualization (with the relevant model table in appendix).
Here we arbitrarily model the odd and even ID’ed cases separately to illustrate what a multi-model graphic might look like using the DD coefficients and their SEs.
model_2period_odds <- feols(Y ~ period * treat | id, sim_2_period %>% filter(id %% 2 == 1))## The variable 'treat' has been removed because of collinearity (see $collin.var).model_2period_evens <- feols(Y ~ period * treat | id, sim_2_period %>% filter(id %% 2 == 0))## The variable 'treat' has been removed because of collinearity (see $collin.var).coef_2period <- tidy(model_2period) %>%
as_tibble() %>%
mutate(model = "Overall")
coef_2period_odds <- tidy(model_2period_odds) %>%
as_tibble() %>%
mutate(model = "Odds")
coef_2period_evens <- tidy(model_2period_evens) %>%
as_tibble() %>%
mutate(model = "Evens")
model_coefs <- bind_rows(coef_2period, coef_2period_odds, coef_2period_evens) %>%
filter(str_detect(term, "treat"))
ggplot(model_coefs, aes(x = estimate, y = model,
xmin = estimate - 1.96 * std.error,
xmax = estimate + 1.96 * std.error)) +
geom_errorbarh() +
geom_point() +
geom_vline(xintercept = 0) +
theme_bw() +
labs(x = "\nDD Coefficient", y = "Model Specification\n")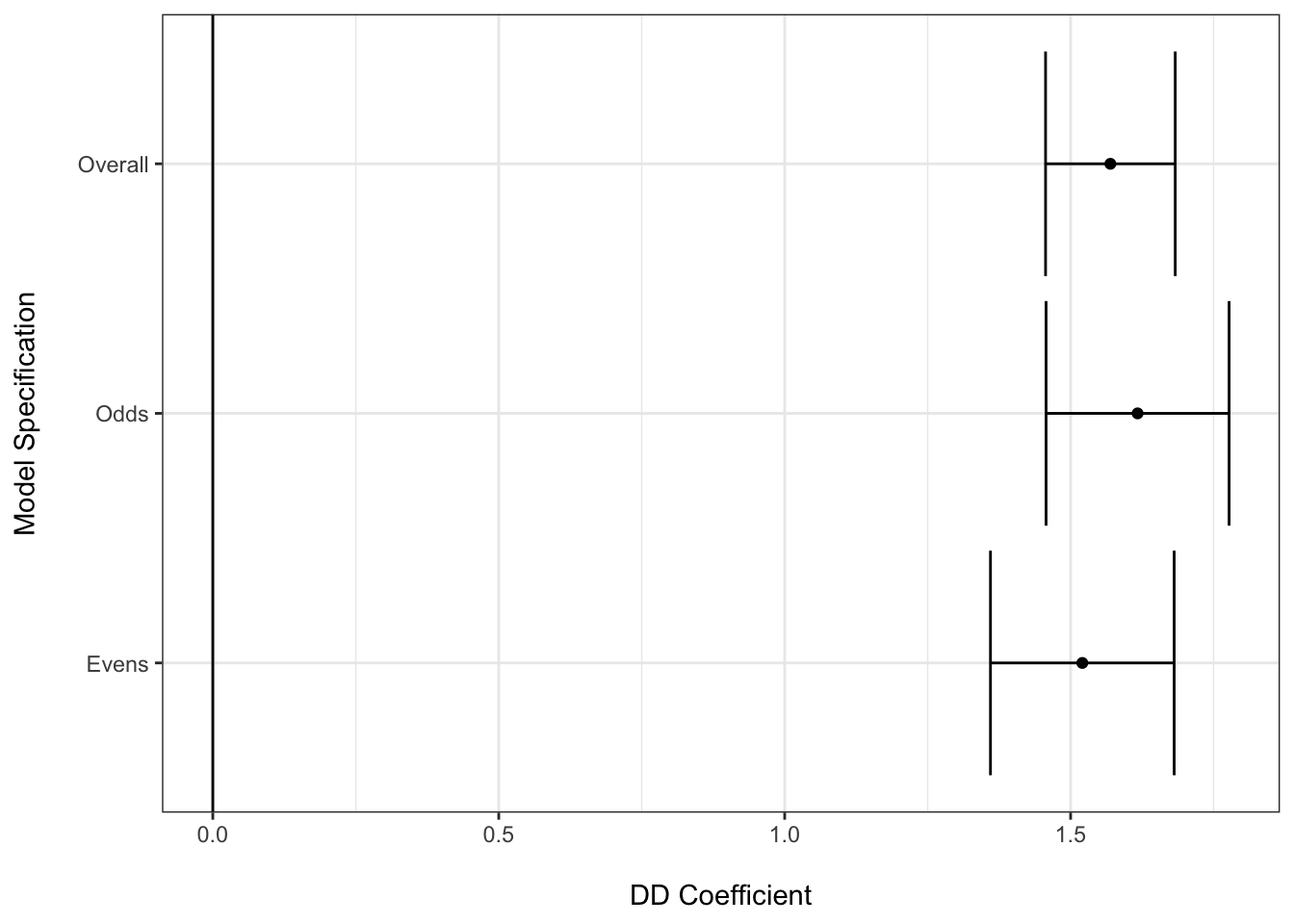
Multiple time periods
Nonetheless, in instances where we have greater complexity to the study design, a figure illustrating the average treatment effects–whether group-time specific or averaged over these groups–can be useful.
Following the vignette from the did package website, we can use the following code to estimate the group-time average treatment effects without covariates.
# estimate group-time average treatment effects without covariates
mw.attgt <- att_gt(yname = "lemp",
gname = "first.treat",
idname = "countyreal",
tname = "year",
xformla = ~ 1,
data = mpdta,
)
# summarize the results
summary(mw.attgt) ##
## Call:
## att_gt(yname = "lemp", tname = "year", idname = "countyreal",
## gname = "first.treat", xformla = ~1, data = mpdta)
##
## Reference: Callaway, Brantly and Pedro H.C. Sant'Anna. "Difference-in-Differences with Multiple Time Periods." Journal of Econometrics, Vol. 225, No. 2, pp. 200-230, 2021. <https://doi.org/10.1016/j.jeconom.2020.12.001>, <https://arxiv.org/abs/1803.09015>
##
## Group-Time Average Treatment Effects:
## Group Time ATT(g,t) Std. Error [95% Simult. Conf. Band]
## 2004 2004 -0.0105 0.0243 -0.0777 0.0567
## 2004 2005 -0.0704 0.0328 -0.1612 0.0204
## 2004 2006 -0.1373 0.0403 -0.2487 -0.0258 *
## 2004 2007 -0.1008 0.0341 -0.1952 -0.0064 *
## 2006 2004 0.0065 0.0235 -0.0585 0.0716
## 2006 2005 -0.0028 0.0188 -0.0548 0.0493
## 2006 2006 -0.0046 0.0181 -0.0548 0.0456
## 2006 2007 -0.0412 0.0208 -0.0988 0.0164
## 2007 2004 0.0305 0.0145 -0.0096 0.0706
## 2007 2005 -0.0027 0.0160 -0.0470 0.0416
## 2007 2006 -0.0311 0.0181 -0.0812 0.0190
## 2007 2007 -0.0261 0.0163 -0.0713 0.0191
## ---
## Signif. codes: `*' confidence band does not cover 0
##
## P-value for pre-test of parallel trends assumption: 0.16812
## Control Group: Never Treated, Anticipation Periods: 0
## Estimation Method: Doubly RobustThere is a default plot method for the did package that enables you to avoid making the plot for yourself.
# plot the results
# set ylim so that all plots have the same scale along y-axis
ggdid(mw.attgt, ylim = c(-.3, .3), type = "calendar")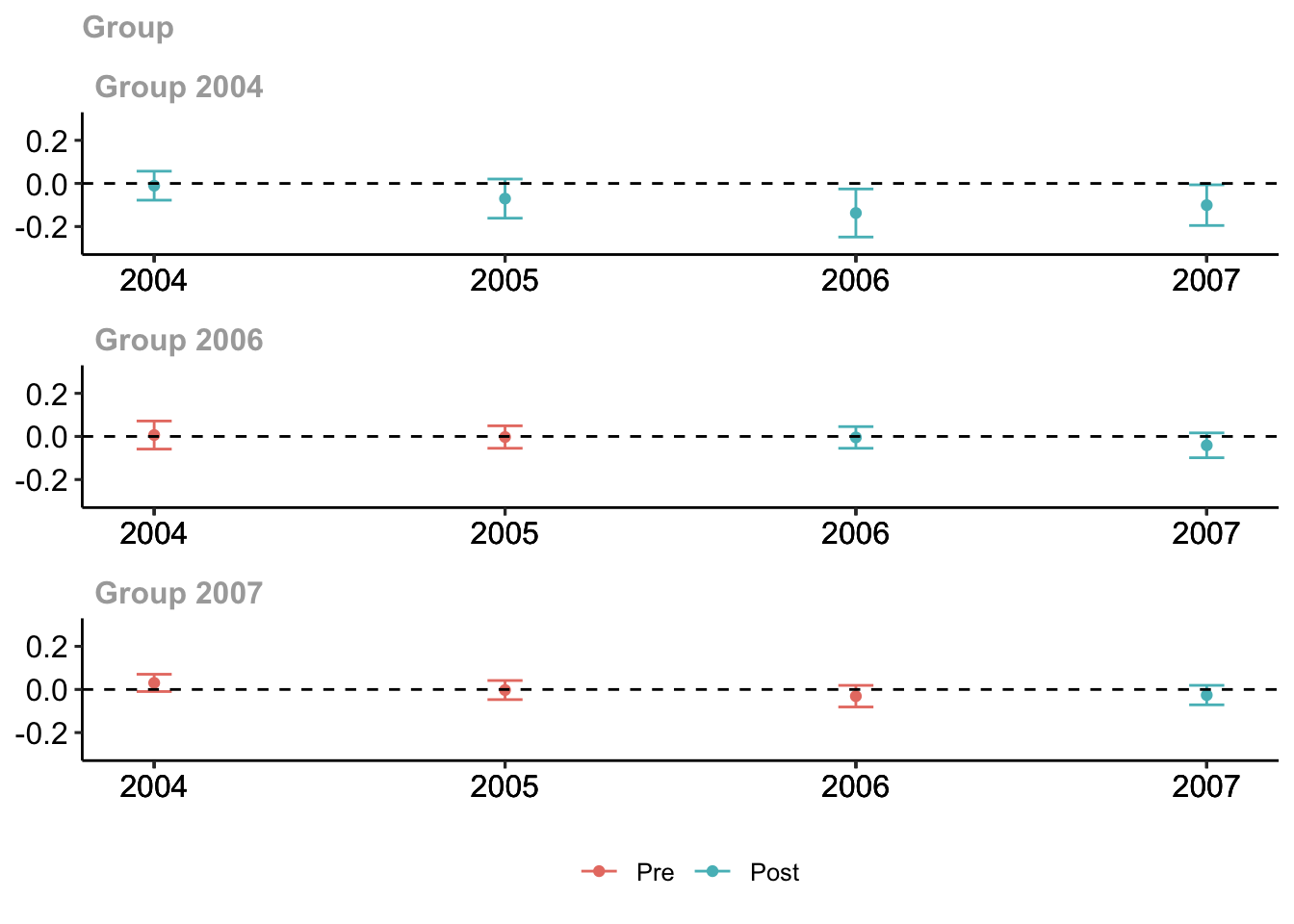
A note about using color in figures
There are some accessibility issues with the default plot that may motivate modifications. Most important is that the default ggplot red and blue colors collapse to very similar shades of gray when printed in black and white. This is emblematic of a general problem that has to be grappled with when producing visualizations for published research articles.
See the interpretability of the figure (cropped for size) from the Callaway and Sant’anna (2021) article in color:
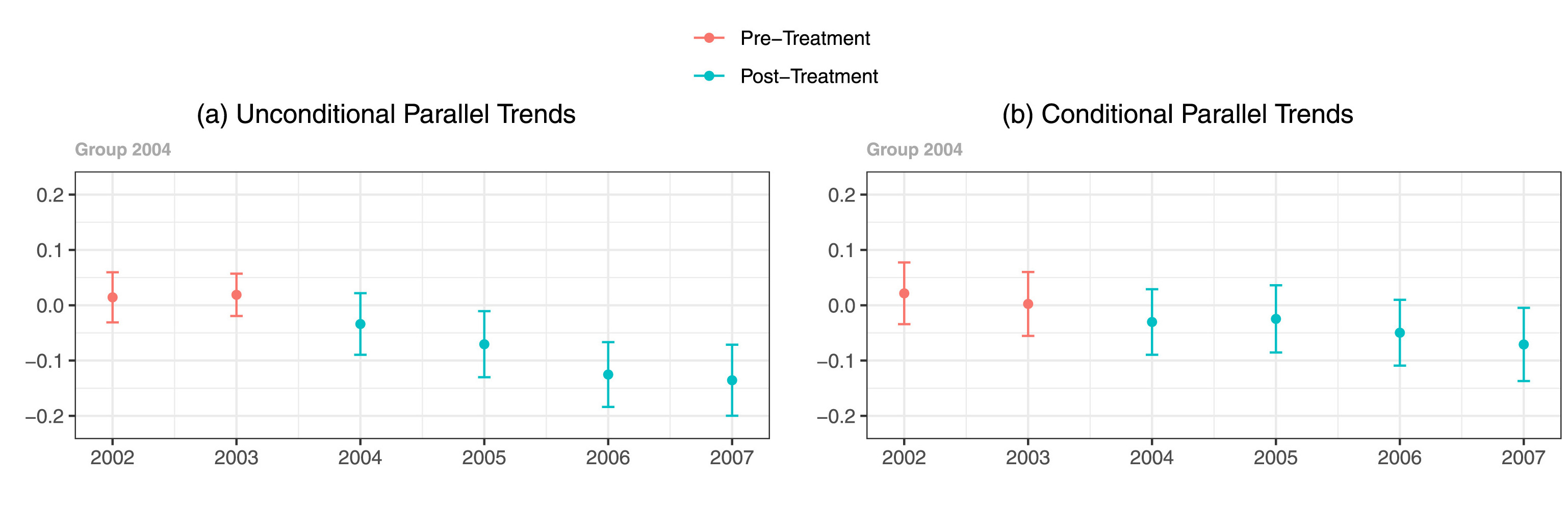
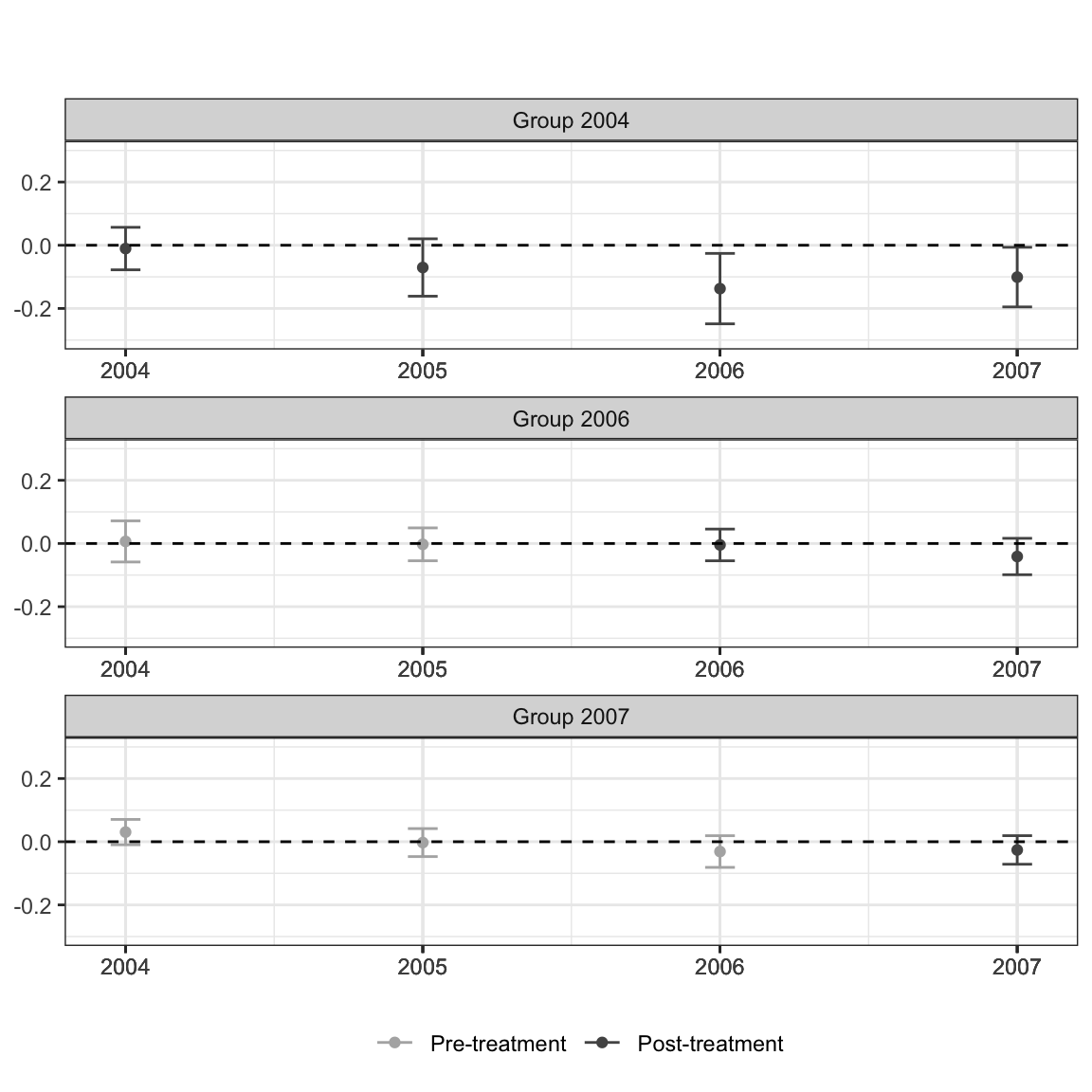
Compared to in grayscale:
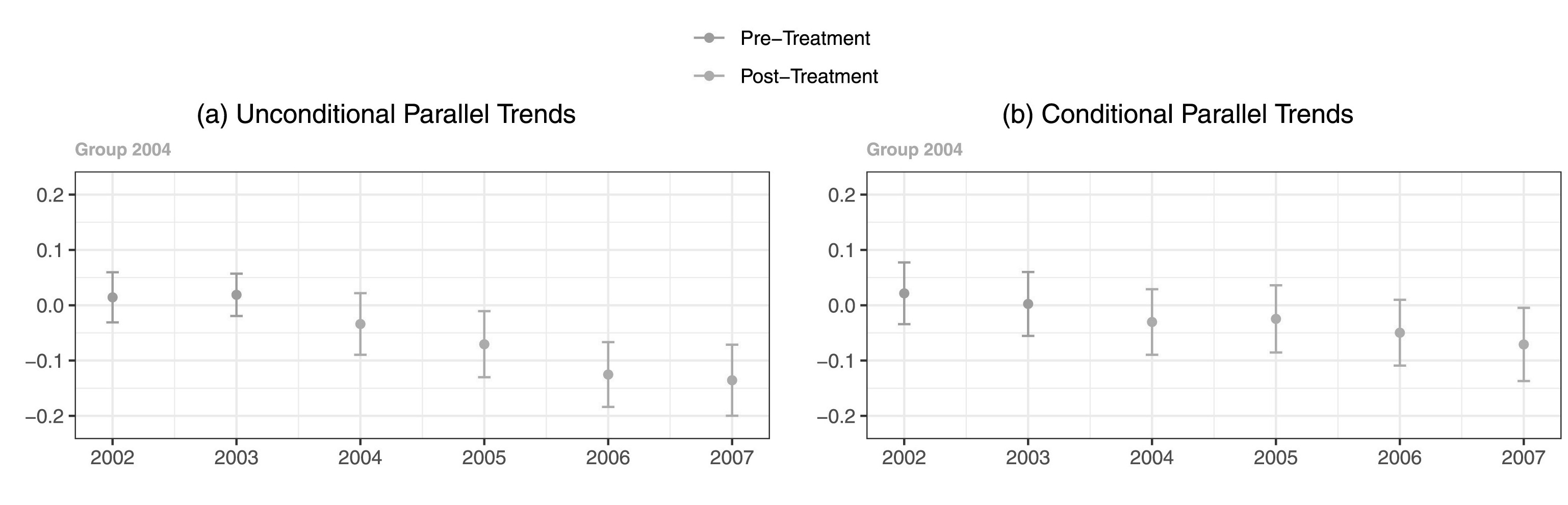
It’s not impossible, but takes a lot more scrutiny to see the residual differences in shade once the blue and red hues are taken away.
While you do occasionally see folks punt and add a “you need to be looking at a PDF to see the color version and only this color version makes sense” caption to figures in an article, this is a case where we can easily make a change to have a color rich version for digital viewers, but a still comprehensible solution for print viewers.
Enter: viridis. You have probably already seen this palette in use and maybe you are even already a user yourself, but for any who are not familiar this is a wonderful tool for effective data visualization with color. All variations on the color palette change in their hue (i.e. RGB values) but also value (grayscale). This means that, by default, the colors flatten to grays that should still perceptibly differ. Using discrete or binned values is a surefire way to ensure this is the case, since 4 or 5 levels of gray tend to be reasonably decipherable.
Thankfully, you can also pass theming = FALSE to ggdid() to have it produce an ATT plot but let you handle the theming yourself. There does not seem to be an easy way to manipulate the aesthetics of this plot (e.g., add a shape aesthetic for pre/post), unfortuantely, but you can make some useful modifications to your liking.
# plot the results
# set ylim so that all plots have the same scale along y-axis
ggdid(mw.attgt, ylim = c(-.3, .3), type = "calendar", theming = FALSE) +
scale_color_viridis_d(begin = .75, end = .25, labels = c("Pre-treatment", "Post-treatment")) +
theme_bw() +
theme(legend.position = "bottom") +
labs(title = "", subtitle = "")## Scale for 'colour' is already present. Adding another scale for 'colour',
## which will replace the existing scale.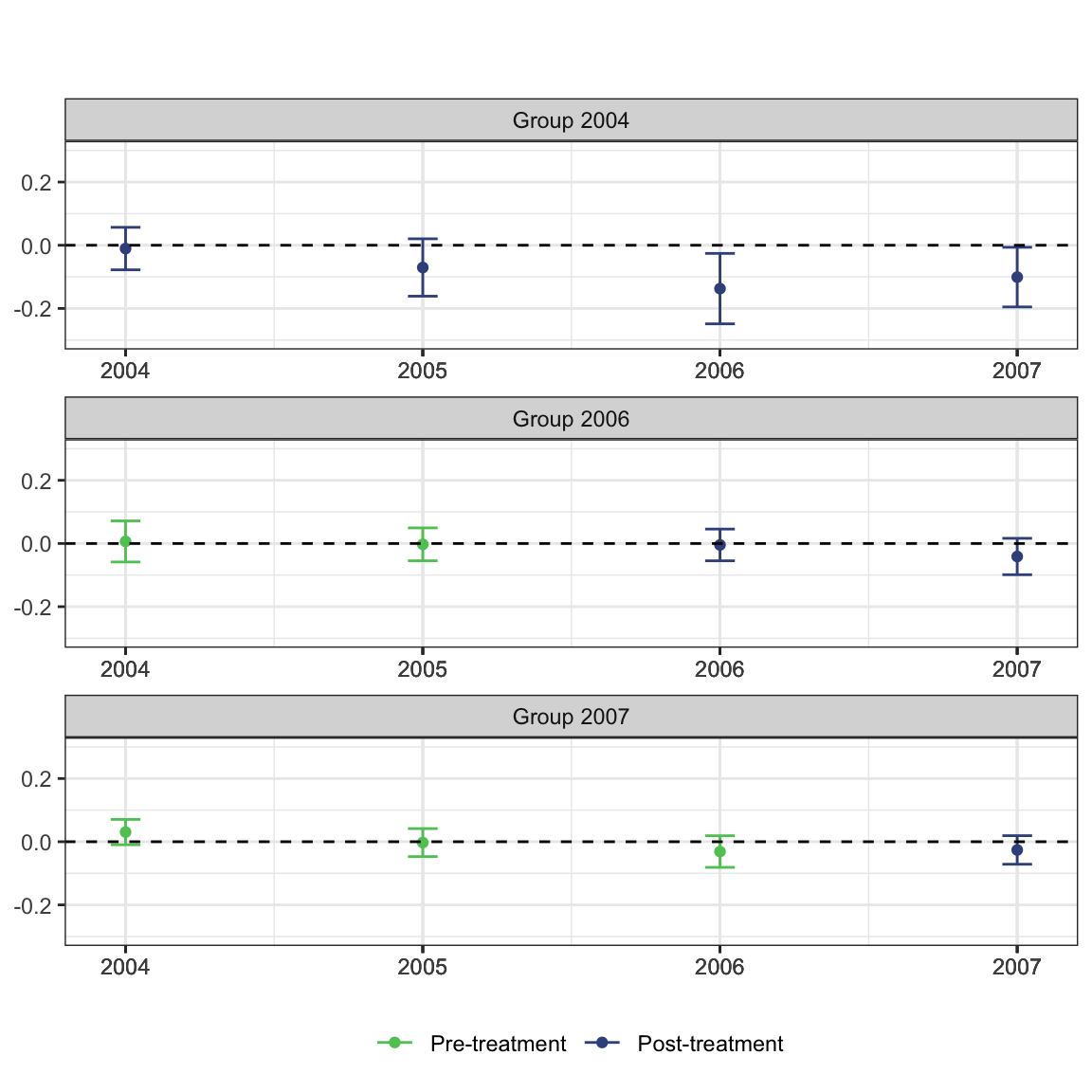
and, what would folks viewing our figure in print see?
How do the treatment effects vary by length of exposure?
#aggregate the group-time average treatment effects
mw.dyn <- aggte(mw.attgt, type = "dynamic")
#print the summary output
summary(mw.dyn)##
## Call:
## aggte(MP = mw.attgt, type = "dynamic")
##
## Reference: Callaway, Brantly and Pedro H.C. Sant'Anna. "Difference-in-Differences with Multiple Time Periods." Journal of Econometrics, Vol. 225, No. 2, pp. 200-230, 2021. <https://doi.org/10.1016/j.jeconom.2020.12.001>, <https://arxiv.org/abs/1803.09015>
##
##
## Overall summary of ATT's based on event-study/dynamic aggregation:
## ATT Std. Error [ 95% Conf. Int.]
## -0.0772 0.0204 -0.1173 -0.0372 *
##
##
## Dynamic Effects:
## Event time Estimate Std. Error [95% Simult. Conf. Band]
## -3 0.0305 0.0142 -0.0044 0.0654
## -2 -0.0006 0.0136 -0.0340 0.0328
## -1 -0.0245 0.0145 -0.0600 0.0111
## 0 -0.0199 0.0122 -0.0500 0.0101
## 1 -0.0510 0.0172 -0.0933 -0.0086 *
## 2 -0.1373 0.0385 -0.2318 -0.0427 *
## 3 -0.1008 0.0358 -0.1888 -0.0128 *
## ---
## Signif. codes: `*' confidence band does not cover 0
##
## Control Group: Never Treated, Anticipation Periods: 0
## Estimation Method: Doubly Robust#use the default plot method
ggdid(mw.dyn, ylim = c(-.3, .3))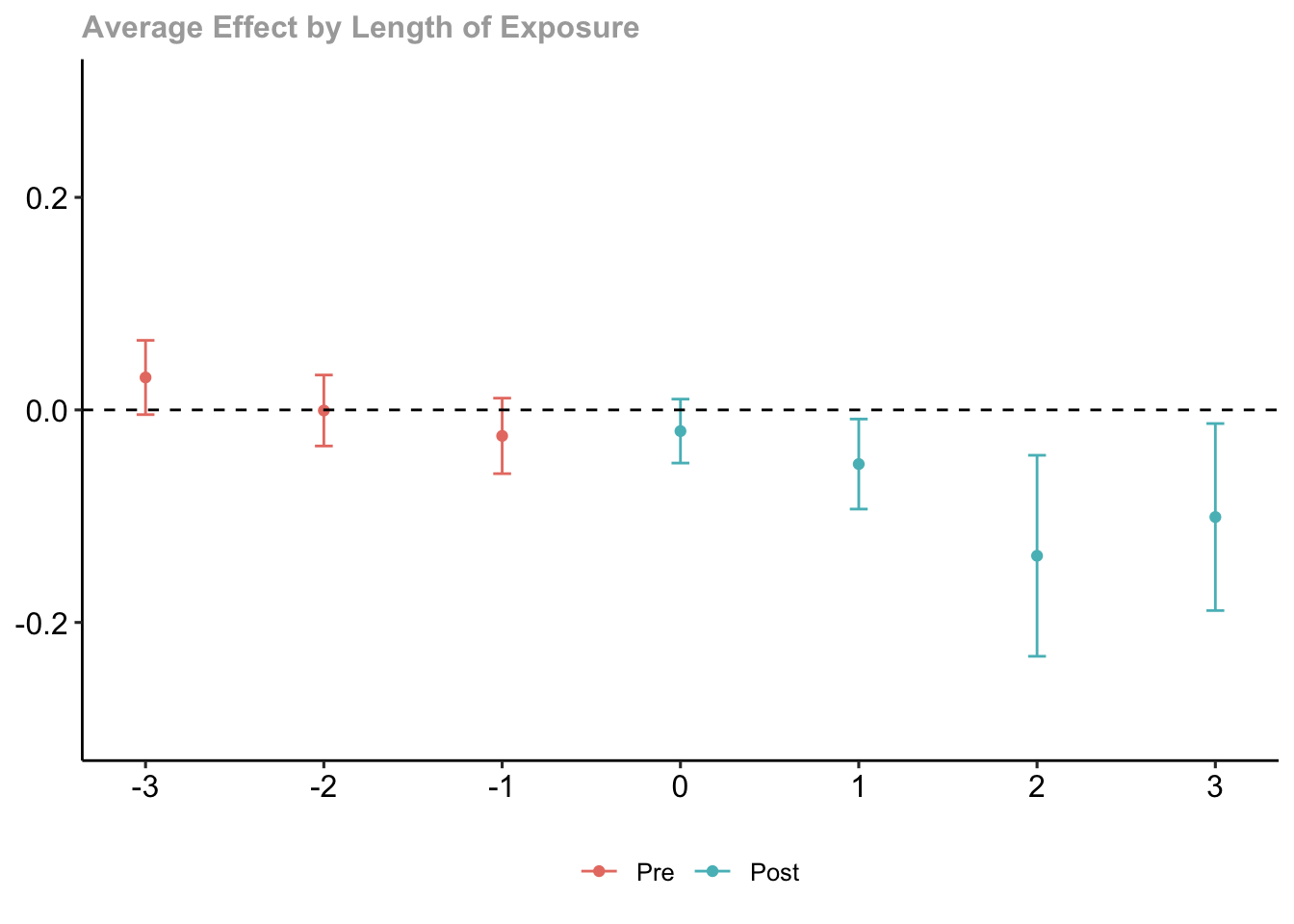
# plot the results
# set ylim so that all plots have the same scale along y-axis
ggdid(mw.dyn, ylim = c(-.3, .3), type = "dynamic", theming = FALSE) +
scale_color_viridis_d(begin = .75, end = .25, labels = c("Pre-treatment", "Post-treatment")) +
theme_bw() +
theme(legend.position = "bottom") +
labs(title = "", subtitle = "")## Scale for 'colour' is already present. Adding another scale for 'colour',
## which will replace the existing scale.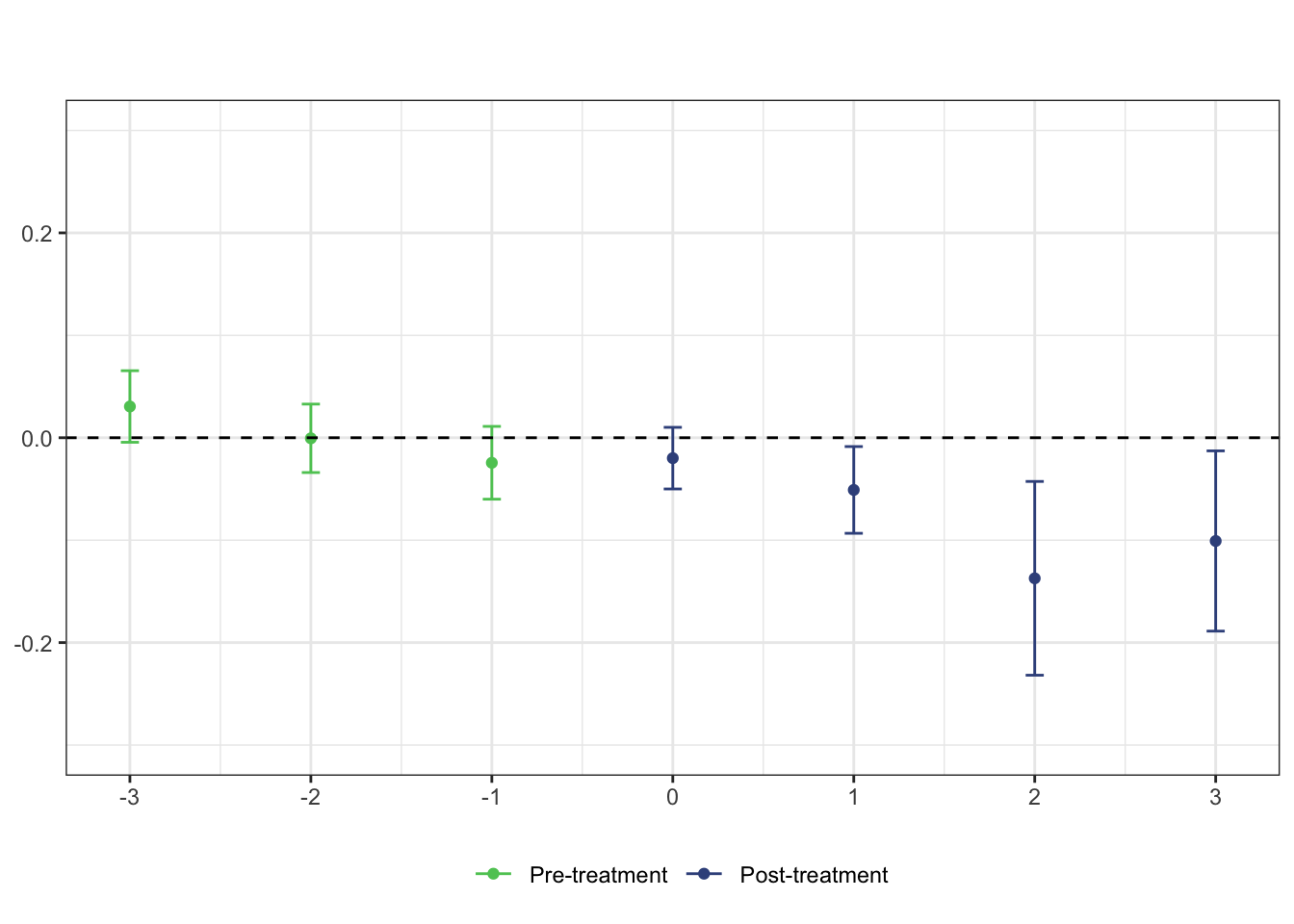
Hands-on: Use the injury data or your own data to make graphics for a DD model
The following hands-on practice uses data from the following article.
B.D. Meyer, W.K. Viscusi, and D.L. Durbin (1995), “Workers’ Compensation and Injury Duration: Evidence from a Natural Experiment,” American Economic Review 85, 322-340.
Since these are data from an R library, you can view the codebook here.
Model the data for Kentucky (ki) and Michigan (mi) separately. Make log(durat) the dependent variable, afchnge the policy change dummy variable (i.e., 1 = after policy change) and highearn the dummy variable for high earners (i.e., 1 = high earner).
injury <- read_csv("./data/injury.csv")## Rows: 7150 Columns: 30
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (30): durat, afchnge, highearn, male, married, hosp, indust, injtype, ag...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(injury)## Rows: 7,150
## Columns: 30
## $ durat <dbl> 1, 1, 84, 4, 1, 1, 7, 2, 175, 60, 29, 30, 100, 4, 2, 1, 1, 2,…
## $ afchnge <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ highearn <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ male <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1…
## $ married <dbl> 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1…
## $ hosp <dbl> 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0…
## $ indust <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 1, 1…
## $ injtype <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ age <dbl> 26, 31, 37, 31, 23, 34, 35, 45, 41, 33, 35, 25, 39, 27, 24, 2…
## $ prewage <dbl> 404.9500, 643.8250, 398.1250, 527.8000, 528.9375, 614.2500, 5…
## $ totmed <dbl> 1187.57324, 361.07855, 8963.65723, 1099.64832, 372.80188, 211…
## $ injdes <dbl> 1010, 1404, 1032, 1940, 1940, 1425, 1110, 1207, 1425, 1010, 1…
## $ benefit <dbl> 246.8375, 246.8375, 246.8375, 246.8375, 211.5750, 176.3125, 2…
## $ ky <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ mi <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ ldurat <dbl> 0.0000000, 0.0000000, 4.4308167, 1.3862944, 0.0000000, 0.0000…
## $ afhigh <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ lprewage <dbl> 6.003764, 6.467427, 5.986766, 6.268717, 6.270870, 6.420402, 6…
## $ lage <dbl> 3.258096, 3.433987, 3.610918, 3.433987, 3.135494, 3.526361, 3…
## $ ltotmed <dbl> 7.079667, 5.889095, 9.100934, 7.002746, 5.921047, 5.351953, 4…
## $ head <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ neck <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ upextr <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ trunk <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ lowback <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ lowextr <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ occdis <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ manuf <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1…
## $ construc <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ highlpre <dbl> 6.003764, 6.467427, 5.986766, 6.268717, 6.270870, 6.420402, 6…